

Tout le monde parle de DeepSeek en ce moment. Les gens n’arrêtent pas de parler de la façon dont cette entreprise a réussi à faire « l’impossible ». Mais comment DeepSeek a-t-il réussi à réduire ses coûts d’entraînement ?

Alors que l’entraînement de modèles IA est généralement coûteuse et gourmande en ressources, DeepSeek a trouvé un moyen d’entraîner ses modèles pour seulement 1/30e du coût habituel.
De nos jours, tout le monde prétend être « à la pointe du progrès », mais DeepSeek prouve qu’il ne suffit plus d’être le « meilleur ». Il s’agit de repousser les limites et de réaliser ce que d’autres pensaient impossible.
Comme je semble l’avoir déjà dit, les géants américains comme OpenAI, Google et Meta ont habitué le monde sur l’idée qu’il fallait dépenser des centaines de millions de dollars pour entraîner et perfectionner leurs modèles AI.
Toutefois un acteur chinois ayant moins de cinq (05) ans d’âge a récemment bouleversé la donne causant une panique générale et multidimensionnelle faisant écrouler les marchés financiers et causant d’énormes pertes financières pour les entreprises tech américaines de la Silicon Valley.
Tu l’as bien compris, il s’agit bel et bien de DeepSeek AI dont l’entraînement n’a coûté que $5 millions de dollars.
Dans cet article, je te propose d’explorer comment DeepSeek a-t-il réussi à réduire ses coûts d’entraînement révolutionnant à jamais l’intelligence artificielle et son accessibilité au plus grand nombre.
Tant mieux dire que la Chine a fait fort : ils ont affirmé un certain leadership dans l’intelligence artificielle que nombreux ne leur reconnaissaient pas – à mon humble avis.
🎁 Tu es un chef d'entreprise préoccupé à générer plus de croissance pour ton business en cette ère de l'intelligence artificielle ?
J'offre 1h de consultation gratuite à tous les chefs d'entreprises qui lisent mon blog.
💡 Le but est de découvrir vos challenges afin de vous proposer un plan d'action personnalisé pour votre situation particulière.
🟩 Intéressé.e ? Écris-moi: miakassissa@miakassissa.com
Bref, si tu es développeur, entrepreneur ou passionné d’IA, cette analyse va te fasciner.
Table des matières
DeepSeek AI : L’IA Chinoise qui ridiculise les géants américains de la Silicon Valley
Le 26 décembre 2024, alors que la majeure partie du monde occidental de l’IA était en vacances pour Noël, la société chinoise DeepSeek AI a publié son modèle d’utilisation générale DeepSeek-V3 (et son modèle de base), accompagné d’un rapport technique détaillé et d’une démo sur chat.deepseek.com.
Il s’agit de leur dernier modèle de mélange d’experts (MoE: Mixture of Experts) formé sur 14,8T tokens avec 671 milliards au total et 37 milliards de paramètres actifs.
La plupart des gens est consciente des résultats extrêmement impressionnants par rapport à d’autres modèles linguistiques de pointe – les plus notables étant les améliorations substantielles par rapport au modèle Llama 405 milliards de paramètres entraîné avec beaucoup moins de paramètres actifs.

La partie la plus impressionnante de ces résultats concerne toutes les évaluations considérées comme extrêmement difficiles – MATH 500 (qui est un ensemble aléatoire de 500 problèmes provenant de l’ensemble des tests), AIME 2024 (les problèmes mathématiques super difficiles de la compétition), Codeforces (le code de la compétition tel qu’il est présenté dans o3), et SWE-bench Verified (l’ensemble de données amélioré d’OpenAI).
Battre le couple GPT-4o et Claude 3.5 ensemble, et avec une certaine marge, est extrêmement rare et puissant.
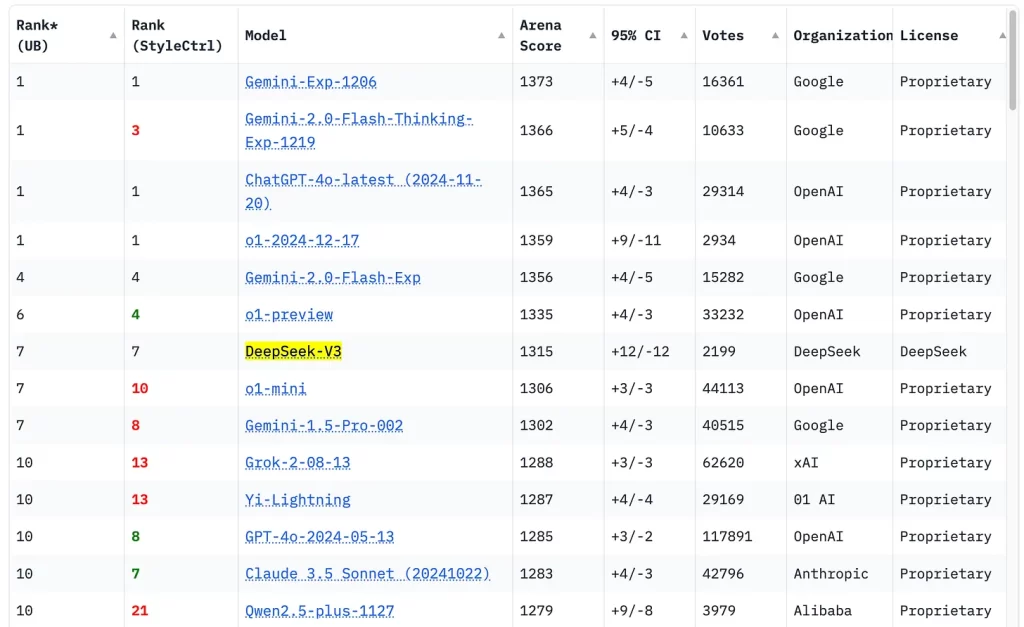
Depuis sa sortie, nous avons également reçu la confirmation du classement de ChatBotArena qui le place dans le top 10 et au-dessus des récents modèles Gemini pro, Grok 2, o1-mini, etc.
Avec seulement 37 milliards de paramètres actifs, c’est extrêmement intéressant pour de nombreuses applications d’entreprise.
📥 Utilise l'IA pour générer des ventes avec ce logiciel de cold outreach (outbound sales) >> Clique ici !
Comment DeepSeek a-t-il réussi à réduire ses coûts d’entraînement
Alors, comment DeepSeek a-t-il réussi à faire cela ?

Décortiquons leur secret de la manière la plus simple possible.
1. Quand les contraintes deviennent un avantage
DeepSeek n’a pas eu accès aux mêmes ressources que ses concurrents américains.
En raison des sanctions américaines, la Chine ne peut plus acheter librement les puces ultra-puissantes comme les NVIDIA H100.
Nombreux sont ceux qui pensaient que les restrictions à l’exportation imposées par les États-Unis sur les puces d’IA avancées limiteraient les capacités de DeepSeek.
Plutôt que de voir cela comme un obstacle, DeepSeek a retourné la situation à son avantage en trouvant des solutions innovantes pour entraîner ses modèles avec moins de puissance de calcul.
DeepSeek AI a prouvé qu’un logiciel de qualité peut compenser les limitations matérielles. Au lieu de s’appuyer sur les derniers GPU haut de gamme comme le NVIDIA H100, ils ont optimisé le matériel dont ils disposaient – probablement le NVIDIA H800, dont la bande passante entre les puces est plus faible.
Les ingénieurs de DeepSeek se sont concentrés sur l’optimisation du code de bas niveau afin de rendre l’utilisation de la mémoire aussi efficace que possible.
Ces améliorations ont permis d’éviter que les performances ne soient entravées par les limites de la puce. En fait, ils ont optimisé ce qu’ils avaient au lieu d’attendre un meilleur matériel.
Ce qu’il faut retenir c’est qu’ils n’ont pas contourné les restrictions – illégalement parlant ; Ils ont simplement fait en sorte que leurs ressources existantes fonctionnent de manière plus intelligente. Et c’est ce qui les rend meilleur à mon humble avis.
En très bref : pas besoin de matériel coûteux – juste un logiciel efficace.


2. Optimisation de l’infrastructure : L’ingénierie invisible mais essentielle
Si un modèle d’IA est un cerveau, son infrastructure est son système nerveux.
DeepSeek a optimisé chaque maillon de la chaîne pour réduire la consommation énergétique et améliorer la vitesse d’entraînement.
PTX : Un langage maison pour optimiser les GPU
DeepSeek a développé son propre langage d’assemblage pour les GPU – PTX: Parallel Thread Execution, optimisant ainsi la communication entre eux.
Résultat ?
✅ Des clusters de calcul 40% plus rapides 📈
✅ Moins de pertes d’efficacité sur du matériel de milieu de gamme
L’entraînement en FP8 : Faire plus avec moins
DeepSeek a adopté la précision mixte FP8 au lieu de FP16 ou FP32, ce qui permet :
✅ 60% d’économie mémoire 💾
✅ Moins d’opérations mathématiques, donc un entraînement plus rapide
Pourquoi c’est important ?
Moins de mémoire consommée = plus de modèles entraînés avec le même budget.

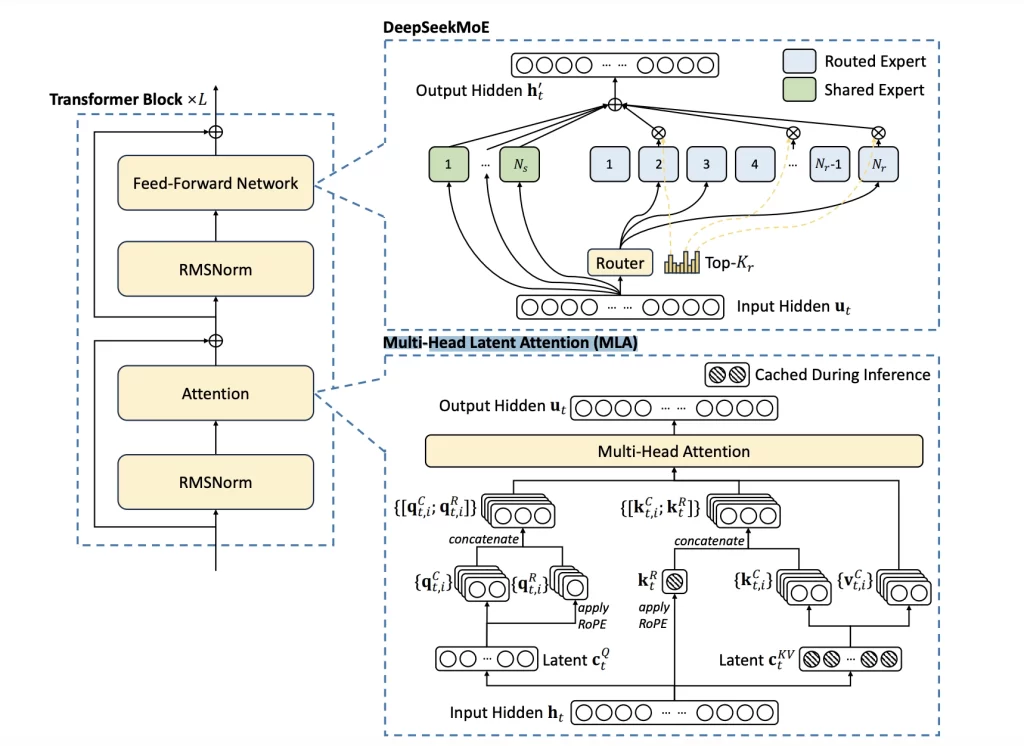
3. DeepSeek MOE : Un modèle géant… qui ne s’active jamais en entier
Les modèles classiques activent tous leurs paramètres à chaque requête, gaspillant ainsi énormément de ressources.
Grâce à une technique appelée équilibrage de charge sans perte auxiliaire – Auxiliary-Loss-Free Load Balancing-, ils ont veillé à ce que seules les parties les plus pertinentes (experts) du modèle soient activées et mises à jour.

DeepSeek a adopté une approche différente :
📌 671 milliards de paramètres, mais seulement 37 milliards activés à chaque requête.
📌 Réduction de 18x des coûts d’inférence, avec une qualité de réponse intacte.
📌 Cela a permis de réduire de 95% l’utilisation des GPU par rapport à Meta…
📌 Un entraînement plus rapide à des coûts nettement inférieurs, sans perte de précision.ce, avec une qualité de réponse intacte.
Comment ?
Grâce au Mixture of Experts (MoE).
Au lieu de faire fonctionner l’intégralité du modèle à chaque interaction, DeepSeek sélectionne seulement les “experts” nécessaires en fonction du contexte.
💡 Leçon clé : Entraîner tout un modèle en permanence est un luxe inutile. La clé, c’est l’activation sélective des parties essentielles.
4. La prédiction multi-tokens : Voir l’avenir pour apprendre plus vite
Les modèles d’IA traditionnels prédisent un mot un token à la fois, ce qui ralentit considérablement l’apprentissage.
DeepSeek a changé cette approche en introduisant la prédiction multi-tokens :
🎯 Prédiction simultanée de plusieurs tokens
🎯 Apprentissage accéléré avec un feedback plus riche
🎯 Meilleure cohérence dans les longues réponses
Pourquoi c’est révolutionnaire ? 🔥
Imagine que tu apprennes à jouer du piano. Si ton professeur te corrige après chaque note, l’apprentissage est lent. Mais si tu reçois une correction globale après plusieurs notes, tu progresses beaucoup plus vite.
C’est exactement ce que DeepSeek a appliqué à son intelligence artificielle.
📥 Utilise l'IA pour générer des ventes avec ce logiciel de cold outreach (outbound sales) >> Clique ici !
5. Compression intelligente des calculs grâce au Multi-Head Latent Attention (MLA)
Les modèles IA ont besoin de mémoires gigantesques pour stocker et traiter leurs calculs.
DeepSeek a réduit cette consommation grâce à une technique de compression avancée « Low-Rank Key-Value (KV) Joint Compression » :
✅ 75% de réduction des paramètres utilisés
✅ Réduction de la charge mémoire sans perte de précision
Grâce à ce système, même des modèles de très grande taille peuvent fonctionner avec moins de ressources.
En bref : une mémoire plus petite, des résultats plus rapides, des coûts moins élevés.
6. Group Relative Policy Optimization (GRPO)
Traditionnellement, l’apprentissage par renforcement (RLHF) nécessite deux modèles : un acteur et un critique.
Mais DeepSeek a trouvé une approche plus efficace :
🔹 12 prédictions générées avec 3 politiques différentes
🔹 Les politiques les plus performantes sont renforcées, sans besoin d’un critique dédié
🔹 Réduction des coûts d’apprentissage de 30%
En supprimant le modèle critique, DeepSeek réduit les besoins en puissance de calcul et en mémoire. Une innovation simple, mais redoutablement efficace.
7. L’open-source comme levier d’innovation
DeepSeek n’a pas gardé toutes ses découvertes secrètes. Leurs modèles et outils sont open-source, ce qui signifie que :
✅ Les entreprises peuvent réutiliser leurs avancées pour leurs propres modèles.
✅ Une communauté contribue à améliorer leurs algorithmes.
En partageant son travail, DeepSeek accélère l’innovation collective et favorise l’émergence de nouveaux acteurs dans l’IA.
Conclusion
L’IA n’est plus réservée aux géants technologiques de la Silicon Valley ou même d’ailleurs.
DeepSeek a prouvé qu’avec des innovations techniques et une optimisation agressive, il est possible de réduire drastiquement les coûts d’entraînement des modèles d’intelligence artificielle.
💡 Les trois leçons clés de leur succès :
1️⃣ Optimisation du matériel et des algorithmes pour maximiser l’efficacité.
2️⃣ Activation sélective des paramètres pour économiser des ressources.
3️⃣ Approches disruptives comme la prédiction multi-tokens pour accélérer l’apprentissage.
Le message à retenir ?
🎁 Tu es un chef d'entreprise préoccupé à générer plus de croissance pour ton business en cette ère de l'intelligence artificielle ?
J'offre 1h de consultation gratuite à tous les chefs d'entreprises qui lisent mon blog.
💡 Le but est de découvrir vos challenges afin de vous proposer un plan d'action personnalisé pour votre situation particulière.
🟩 Intéressé.e ? Écris-moi: miakassissa@miakassissa.com
L’IA de demain ne sera pas dominée par ceux qui ont le plus d’argent… mais par ceux qui savent le mieux utiliser leurs ressources.
🚀 Et toi, quelle innovation de DeepSeek AI t’inspire le plus ? Dis-moi en commentaire ! 👇
Bervillon Glenn MiAKASSiSSA est un Ingénieur DevOps/Cloud Certifié Linux. Enseignant d'Universités privées, Formateur, Consultant et Entrepreneur évoluant en République du Congo depuis 2016, il s'intéresse à l'entrepreneuriat dans toutes ses formes, aux technologies émergentes (Cybersécurité, IA/ML, Blockchain), au Marketing (Digital) et à l'Art de Vendre...












Aucun Commentaire